


Few and Different – Algoritmo Isolation Forest
Artículo publicado en Big Data Magazine por Begoña Vega, Analytics Strategy Expert en Innova-tsn.
La digitalización vertiginosa que estamos viviendo, unida a los avances tecnológicos de las últimas décadas han propiciado una era de oro de la analítica avanzada, gracias a la gran cantidad de datos disponibles y al soporte tecnológico necesario para aplicar determinados algoritmos de una manera más eficiente. En este contexto, el mercado cada día requiere soluciones y modelos predictivos más optimizados y sensibles que no sólo ofrezcan la mejor predicción posible, sino que además sean operables y que añadan un valor tangible al negocio.
A pesar de la abundancia de datos de muchos orígenes, ¿Qué ocurre cuando los eventos que hay que predecir no ocurren de manera frecuente? ¿Es posible ofrecer una predicción ajustada y fiable? En Innova-tsn nos acercamos a un problema como este recientemente: el objetivo de negocio del cliente era optimizar los procesos de reposición de mercancías de varias tiendas con miles de referencias. Para ello, había que abordar una predicción de ventas, considerar el stock y decidir cómo aprovisionar ese abastecimiento, con la dificultad añadida de que la mayoría de las referencias eran de venta esporádica. ¿Cómo llegar a una solución que ofrezca una precisión suficiente, a nivel referencia, para que el resultado sea operable?

Este artículo recoge las conclusiones de un análisis real, en el que estudiamos las diferentes alternativas para acercarnos al problema y evaluamos beneficios y limitaciones de su implementación.
Como introducíamos, en este caso se trataba de realizar, como primer paso para una solución analítica de optimización de reposición, una predicción de ventas de las distintas referencias ofrecidas por un retailer.
En estas situaciones se trata de predecir si un evento (en este caso la venta de la referencia considerada en cada caso) va a ocurrir o no, por lo que lo habitual es entrenar modelos supervisados de clasificación binaria. Para ello, entrenamos el modelo con un histórico de datos en el que se observamos, para distintos momentos y condiciones, si finalmente ocurrió o no el evento. La elección del algoritmo depende del volumen de registros y de la tipología de las variables predictoras. Los algoritmos más habituales cuando nos enfrentamos a un gran volumen de datos son Logistic Regression, Support Vector Machines, K-Nearest Neighbours, y los ensamblados, que suelen dar mejores resultados, como son el Random Forest, AdaBoost, Gradient Boosting, etc.
En nuestro caso, además, teníamos una casuística particular para algunas de las referencias: nos encontrábamos con casos de venta muy esporádica, en los que según el histórico, la probabilidad de ocurrencia del evento (la venta) era muy baja (0.15%).
Cuando la probabilidad del evento es tan baja la predicción se hace más compleja, tienes menos ocurrencias en el histórico disponible y la modelización es un reto. En nuestro caso, la bajísima tasa de conversión nos permitió pensar en la posibilidad de otro enfoque, en el que trato la conversión como una anomalía en un conjunto donde “lo normal” es que no pase nada (que no ocurra esa venta).
¿Y qué es una anomalía? D.M. Hawkins definió las anomalías en su libro Identification of Outliers [1] como “una observación que se desvía tanto de otras observaciones como para despertar sospechas de que fue generado por un mecanismo diferente”.
Así pues, las anomalías son ocurrencias muy poco frecuentes que suelen tener comportamientos o patrones diferentes al resto. Encontrar esos patrones en los datos es precisamente la tarea de los algoritmos de detección de anomalías, que se consideran, además, No Supervisados puesto que no suele ser habitual tener identificados los casos atípicos a priori.
Uno de los algoritmos que más se utiliza para esta tarea es el Isolation Forest [2], inspirado en el algoritmo de clasificación Random Forest: El modelo está formado por combinaciones de múltiples árboles, los cuales se van generando de forma recursiva mediante la creación de ramas, hasta que cada una de las observaciones queda aislada en un nodo terminal.
Al contrario que en los Random Forest, que son supervisados, en los Isolation Forest, la selección de los puntos de división de cada rama se hace de manera aleatoria. Así pues, aquellas observaciones con características distintas al resto quedarán aisladas en pocos pasos.
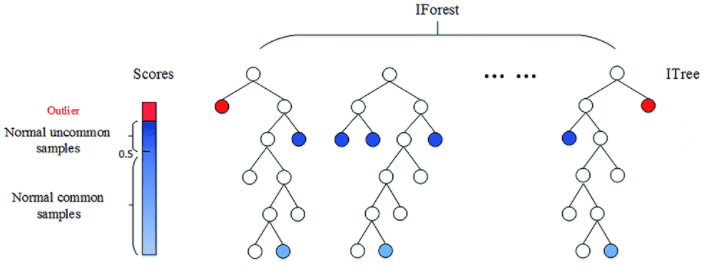
Este algoritmo atribuye a cada observación un score que se calcula como la media del número de subdivisiones que han sido necesarias para aislar dicha observación en el conjunto de valores. Cuanto menor es este valor, mayor probabilidad de que se trate de una anomalía. Por consiguiente, aquellas observaciones con el score más bajo serán las anomalías, siendo así el reto encontrar el punto de corte adecuado para determinar qué observaciones se consideran atípicas (Fig.2).
Isolation Forest está considerado como el “Best in class” entre los algoritmos de detección de anomalías. Su buena fama está justificada: su lógica es sencilla, la convergencia se alcanza relativamente rápido y escala muy bien, creciendo su complejidad con el número de registros de manera lineal.
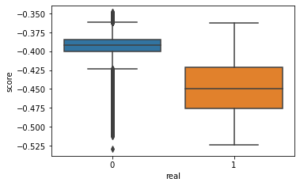
Asimismo, en nuestro caso, conocemos el resultado de la clasificación. Esto quiere decir que sabemos si el evento finalmente ocurrió, por lo que es relativamente sencillo validar el resultado y establecer un punto de corte para la clasificación. Este punto de corte, que se conoce como parámetro de contaminación, suele establecerse como el valor de la probabilidad del evento. Así lo hicimos en nuestro caso, quedando en el 0.15%.
Por lo tanto, en nuestra investigación, entrenamos varios modelos Isolation Forest con diferentes parámetros con los casos típicos como muestra de entrenamiento, dejando como conjunto de validación aquel en el que había tanto valores típicos como anomalías (0’s y 1’s).
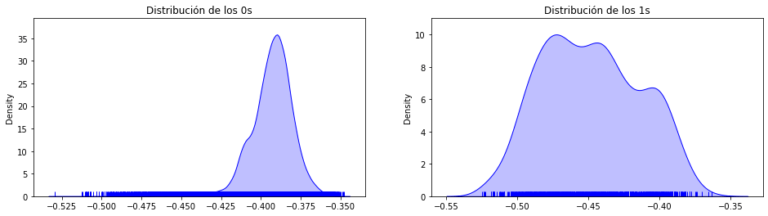
Por otro lado, también entrenamos varios modelos supervisados con distintas configuraciones, y finalmente, comparamos las métricas de rendimiento del Iforest con las de aquellos algoritmos supervisados cuyas configuraciones nos habían arrojado mejores resultados.
En nuestro caso, las métricas de rendimiento del Iforest se quedaron muy cerca de las de los mejores algoritmos supervisados, aunque ligeramente por debajo. No olvidemos que los algoritmos supervisados juegan con “la ventaja” de conocer de antemano la clasificación y en cada iteración van buscando la manera de mejorar el porcentaje de clasificaciones correctas, mientras que Isolation Forest simplemente divide de manera aleatoria sin un objetivo de clasificación.
En concreto, el AUC conseguido por el Iforest para el conjunto de test fue del 92.1% frente al 96.6% del Random Forest y el 96.3% del LogisticRegression. (Fig.4)
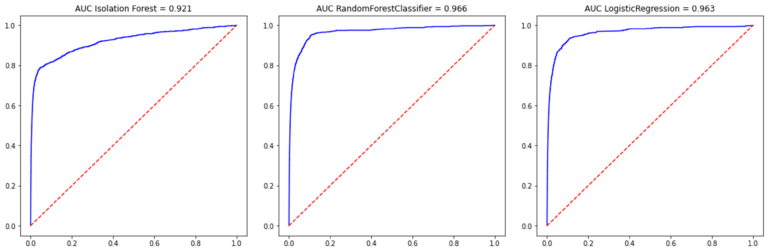
En consecuencia, constatamos que los resultados del IForest, sin ser tan buenos como los alcanzados con los algoritmos supervisados, son francamente satisfactorios.
¿Dónde vemos que puede ser interesante aplicar este algoritmo?
En concreto, vemos muy interesante la aplicación de este tipo de algoritmos en casos de fraude eléctrico, donde la tasa del mismo es muy baja, pero no es posible tener etiquetados dichos casos de fraude por el elevado coste de la inspección a cada uno de los puntos de suministro. El poder proporcionar una lista reducida de puntos sospechosos identificados con este algoritmo posibilita detectar un alto volumen de fraude reduciendo notablemente el coste. El hecho de aplicar IForest, que es un algoritmo no supervisado, hace que no sea necesario tener un histórico de casos clasificados como fraude.
Esto mismo aplica a cualquier problema de identificación de fraude (financiero, en los TPV de tiendas de grandes cadenas, en las compañías aseguradoras, etc.) donde la identificación de una lista reducida de perfiles sospechosos es vital para la detección de potenciales fraudes.
Otras áreas de posible uso de este algoritmo son la industria y la ciberseguridad. En el primer caso, la industria, la detección de anomalías podría indicar cuándo hay que realizar mantenimiento de la maquinaria, ahorrando costes en mantenimientos no necesarios y evitando daños mayores, anticipándose a la avería. En el campo de la ciberseguridad, se puede aplicar mediante la detección de intrusiones en las redes a través de la vigilancia e identificación de actividad anómala.
Como vemos, los campos de aplicación son numerosos y variados, por lo que desde el área de Advanced Analytics apostamos por abordar esta línea de trabajo en futuros proyectos. Gracias a esto, sumado a la integración de los sistemas predictivos en las soluciones poniendo al cliente en el centro de la estrategia, Innova-tsn logra ofrecer un sistema integral completo.
Referencias
[1] Hawkins, D. M. (1980). Identification of outliers. London [u.a.]: Chapman and Hall. ISBN: 041221900X
[2] F. T. Liu, K. M. Ting and Z. Zhou, «Isolation Forest,» 2008 Eighth IEEE International Conference on Data Mining, 2008, pp. 413-422, doi: 10.1109/ICDM.2008.17.