Innova-tsn ha vuelto a participar en el encuentro anual de Knowledge Discover and Data Mining (KDD) en su edición de 2021. Esta conferencia interdisciplinar aúna a profesionales de la ciencia de los datos, Advanced Analytics y Big Data, entre otros. El KDD Congress, después de más de 30 años, sigue siendo el encuentro más grande y antiguo de este sector, manteniéndose a la vanguardia tecnológica. Este congreso virtual conecta a los científicos del dato y expertos a través de una competición en la que se proponen soluciones inteligentes a desafíos y casos reales.
Para esta edición de 2021, Innova-tsn, ha competido en dos casos o challenges diferentes: City Brain Challenge, con un equipo de Innova-tsn al 100% y Multi-dataset Time Series Anomaly Detection, junto a otras tres personas de la Universidad Complutense de Madrid.
City Brain Challenge situaba el problema en una red de carreteras de una ciudad, teniendo que optimizar la afluencia de vehículos minimizando el retraso. El objetivo era el desarrollo de un modelo automatizado de selección de fases, y su coordinación, de los semáforos en las intersecciones de la ya mencionada red de carreteras. Innova-tsn logró posicionarse en el Top 40 mundial en esta prueba.
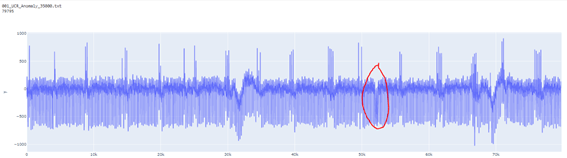
Por otro lado, Multi-dataset Time Series Anomaly Detection planteaba encontrar una solución para la detección de anomalías en series temporales univariantes. En este desafío, Innova-tsn obtuvo una posición dentro del Top 25 mundial.
Challenge 1: CITY BRAIN CHALLENGE
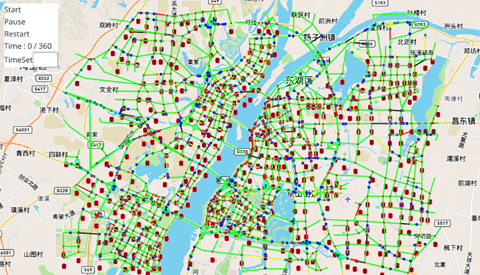
El reto propuesto en este caso consistía en optimizar la gestión de una red de carreteras similar a la que tendría una gran ciudad.
Para lograrlo, se partía con información sobre una red de carreteras a escala de la ciudad y de su demanda de tráfico. El objetivo es gestionar todos los semáforos de las distintas intersecciones de la red, tratando de organizar eficiente y eficazmente la cantidad del tráfico y su fluidez.
Para entender mejor el problema, se muestra la siguiente figura, donde se puede ver la estructura de las intersecciones que habría que administrar, así como las posibles señales de paso: