


Few and Different – Algoritmo Isolation Forest
Article publicat a Big Data Magazine de Begoña Vega, Analytics Strategy Expert a Innova-tsn.
La digitalització vertiginosa que estem vivim, unida als avenços tecnològics de les darreres dècades han propiciat una era d’or de l’analítica avançada gràcies a la gran quantitat de dades disponibles i al suport tecnològic necessari per aplicar determinats algoritmes d’una manera més eficient. En aquest context, el mercat cada dia requereix solucions i models predictius més optimitzats i sensibles que no només ofereixin la millor predicció possible, sinó que a més a més, siguin operables i que afegeixin un valor tangible al negoci.
Malgrat l’abundància de dades de molts orígens, què ocorre quan els esdeveniments que cal predir no ocorren de manera freqüent? És possible oferir una predicció ajustada i fiable? A Innova-tsn ens vam apropar a un problema com aquest recentment: l’objectiu de negoci del client era optimitzar els processos de reposició de mercaderies de diverses botigues amb milers de referències. Per a això, calia abordar una predicció de vendes, considerar l’stock, i decidir com aprovisionar aquell abastament amb la dificultat afegida que la majoria de les referències eren de venda esporàdica. Com arribar a una solució que ofereixi una precisió suficient a nivell referència perquè el resultat sigui operable?

Aquest article recull les conclusions d’una análisis real, en la qual vam estudiar les diferents alternatives per apropar-nos al problema i vam avaluar beneficis i limitacions de la seva implementació.
Com introduíem, en aquest cas es tractava de realitzar, com a primer pas per a una solució analítica d’optimització de reposició, una predicció de vendes de les diferents referències ofertes per un retailer.
En aquestes situacions es tracta de predir si un esdeveniment (en aquest cas la venda de la referència considerada en cada cas) ocorrerà o no, per la qual cosa l’habitual és entrenar models supervisats de classificació binària. Per a això, vam entrenar el model amb un històric de dades en el qual vam observar, per a diferents moments i condicions, si finalment va ocórrer o no l’esdeveniment. L’elecció de l’algoritme depèn del volum de registres i de la tipologia de les variables predictores. Els algoritmes més habituals quan ens enfrontem a un gran volum de dades són Logistic Regression, Support Vector Machines, K-Nearest Neighbours, i els encadellats, que acostumen a donar millors resultats com són el Random Forest, AdaBoost, Gradient Boosting, etc.
A més a més, en el nostre cas, teníem una casuística particular per a algunes de les referències: ens trobàvem amb casos de venda molt esporàdica en els quals, segons l’històric, la probabilitat d’ocurrència de l’esdeveniment (la venda) era molt baixa (0,15%).
Quan la probabilitat de l’esdeveniment és tan baixa la predicció es fa més complexa, tens menys ocurrències a l’històric disponible i la modelització és un repte. En el nostre cas, la baixíssima taxa de conversió ens va permetre pensar en la possibilitat d’un altre enfocament, en el qual tracto la conversió com una anomalia en un conjunt on “el normal” és que no passi res (que no ocorri aquella venda).
I què és una anomalia? D.M. Hawkins va definir les anomalies al seu llibre Identification of Outliers [1] com “una observació que es desvia tant d’altres observacions com per despertar sospites que va ser generada per un mecanisme diferent”.
Així doncs, les anomalies són ocurrències molt poc freqüents que acostumen a tenir comportaments o patrons diferents de la resta. Trobar aquests patrons en les dades és precisament la tasca dels algoritmes de detecció d’anomalies, que, a més a més, es consideren No Supervisats ja que no sol ser habitual tenir identificats els casos atípics a priori.
Un dels algoritmes que més es fa servir per a aquesta tasca és l’Isolation Forest [2], inspirat en l’algoritme de classificació Random Forest: El model està format per combinacions de múltiples arbres, els quals es generen de forma recursiva mitjançant la creació de branques fins que cada una de les observacions queda aïllada en un node terminal.
Al contrari que en els Random Forest, que són supervisats, en els Isolation Forest, la selecció dels punts de divisió de cada branca es fa de manera aleatòria. Així doncs, aquelles observacions amb característiques diferents de la resta quedaran aïllades en pocs passos.
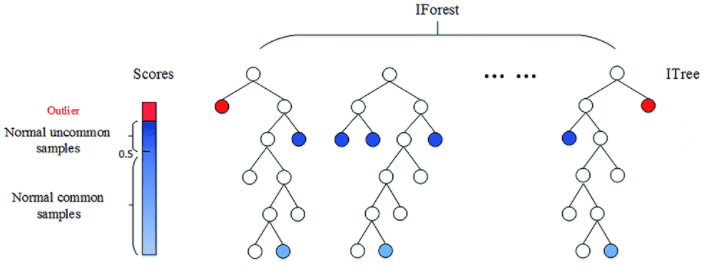
Aquest algoritme atribueix a cada observació un score que es calcula com la mitjana del nombre de subdivisions que han estat necessàries per aïllar dita observació en el conjunt de valors. Com menor és aquest valor, major probabilitat que es tracti d’una anomalia. Per consegüent, aquelles observacions amb l’score més baix seran les anomalies, sent així el repte trobar el punt de tall adequat per determinar quines observacions es consideren atípiques (Fig. 2).
Isolation Forest està considerat com el “Best in class” entre els algoritmes de detecció d’anomalies. La seva bona fama està justificada: la seva lògica és senzilla, la convergència s’ateny relativament ràpid i escala molt bé, creixent la seva complexitat amb el nombre de registres de manera lineal.
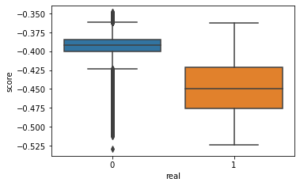
Així mateix, en el nostre cas, coneixem el resultat de la classificació. Això vol dir que sabem si l’esdeveniment finalment va ocórrer, per la qual cosa és relativament senzill validar el resultat i establir un punt de tall per a la classificació. Aquest punt de tall, que es coneix com paràmetre de contaminació, sol establir-se com el valor de la probabilitat de l’esdeveniment. Així ho vam fer en el nostre cas, i va quedar en el 0,15%.
Per tant, en la nostra investigació, vam entrenar diversos models Isolation Forest amb diferents paràmetres amb els casos típics com a mostra d’entrenament, deixant com a conjunt de validació aquell en què hi havia tant valors típics com anomalies (0’s i 1’s).
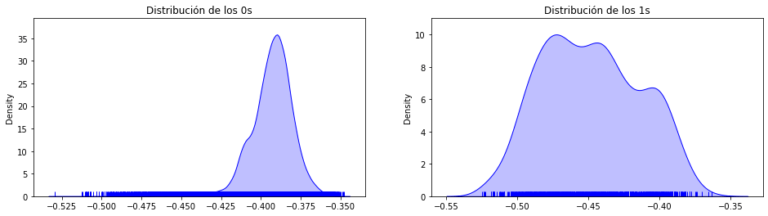
D’altra banda, també vam entrenar diversos models supervisats amb diferents configuracions, i finalment, vam comparar les mètriques de rendiment de l’Iforest amb les d’aquells algoritmes supervisats les configuracions dels quals ens havien llançat millors resultats.
En el nostre cas, les mètriques de rendiment de l’Iforest es van quedar molt a prop de les dels millors algoritmes supervisats, encara que lleugerament per sota. No oblidem que els algoritmes supervisats juguen amb “l’avantatge” de conèixer per endavant la classificació i en cada iteració busquen la manera de millorar el percentatge de classificacions correctes, mentre que Isolation Forest simplement divideix de manera aleatòria sense un objectiu de classificació.
En concret, l’AUC aconseguit per l’Iforest per al conjunt de test va ser del 92,1% davant el 96,6% del Random Forest i el 96,3% del LogisticRegression. (Fig.4)
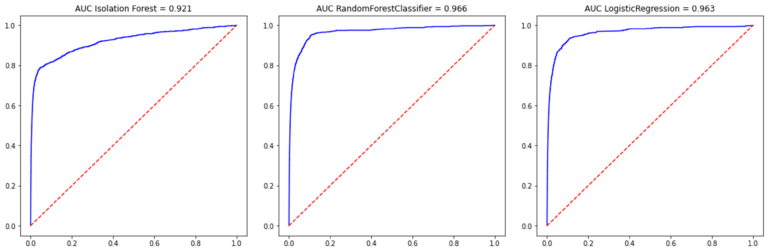
En conseqüència, constatem que els resultats de l’IForest, sense ser tan bons com els atesos amb els algoritmes supervisats, són francament satisfactoris.
On veiem que pot ser interessant aplicar aquest algoritme?
En concret, veiem molt interessant l’aplicació d’aquest tipus d’algoritmes en casos de frau elèctric, on la taxa d’aquest és molt baixa, però no és possible tenir etiquetats dits casos de frau per l’elevat cost de la inspecció a cadascun dels punts de subministrament. Poder proporcionar una llista reduïda de punts sospitosos identificats amb aquest algoritme possibilita detectar un alt volum de frau amb una notable reducció del cost. El fet d’aplicar IForest, el qual és un algoritme no supervisat, fa que no sigui necessari tenir un històric de casos classificats com a frau.
Això mateix aplica a qualsevol problema d’identificació de frau (financer, als TPV de botigues de grans cadenes, a les companyies asseguradores, etc.) on la identificació d’una llista reduïda de perfils sospitosos és vital per a la detecció de potencials fraus.
Altres àrees de possible ús d’aquest algoritme són la indústria i la ciberseguretat. En el primer cas, la indústria, la detecció d’anomalies podria indicar quan cal realitzar manteniment de la maquinària, amb la qual cosa s’estalvien costs en manteniments no necessaris i s’eviten danys majors, anticipant-se a l’avaria. En el camp de la ciberseguretat, es pot aplicar mitjançant la detecció d’intrusions a les xarxes a través de la vigilància i identificació d’activitat anòmala.
Com veiem, els camps d’aplicació són nombrosos i variats, per la qual cosa, des de l’àrea d’Advanced Analytics apostem per abordar aquesta línia de treball en futurs projectes. Gràcies a això, sumat a la integració dels sistemes predictius en les solucions posant el client al centre de l’estratègia, Innova-tsn aconsegueix oferir un sistema integral complet.
Referencias
[1] Hawkins, D. M. (1980). Identification of outliers. London [u.a.]: Chapman and Hall. ISBN: 041221900X
[2] F. T. Liu, K. M. Ting and Z. Zhou, «Isolation Forest,» 2008 Eighth IEEE International Conference on Data Mining, 2008, pp. 413-422, doi: 10.1109/ICDM.2008.17.